Cluster Farmer (Docker)
This guide was created for Gemeni 3h testnet and will be updated to mainnet once released.
Introduction
Before setting up a Cluster Farmer, you should already:
- Have a Node running. Run an Autonomys Node on Docker.
- Have prepped your drives. Prep Your Drives for Autonomys
- Have Docker installed Install Docker on Debian
- Have Portainer Installed Install Portainer Host/Agent
Create an Autonomys Network in Docker
You only need to create the network once for each PC. If you already created it on this PC you can skip this step.
Create the "autonomys-network" we will use to deploy our Autonomys containers on:
sudo docker network create \
--driver bridge \
--subnet 172.25.0.0/16 \
--gateway 172.25.0.1 \
autonomys-network
This creates a new network called "autonomys-network" using the subnet 172.25.0.0/16 and the gateway 172.25.0.1.
Cluster Farmer Architecture
Because of how modular a Cluster is, depending on your setup you may want to deploy only certain parts of the Cluster on certain PCs. Let us start with a minimal Cluster:
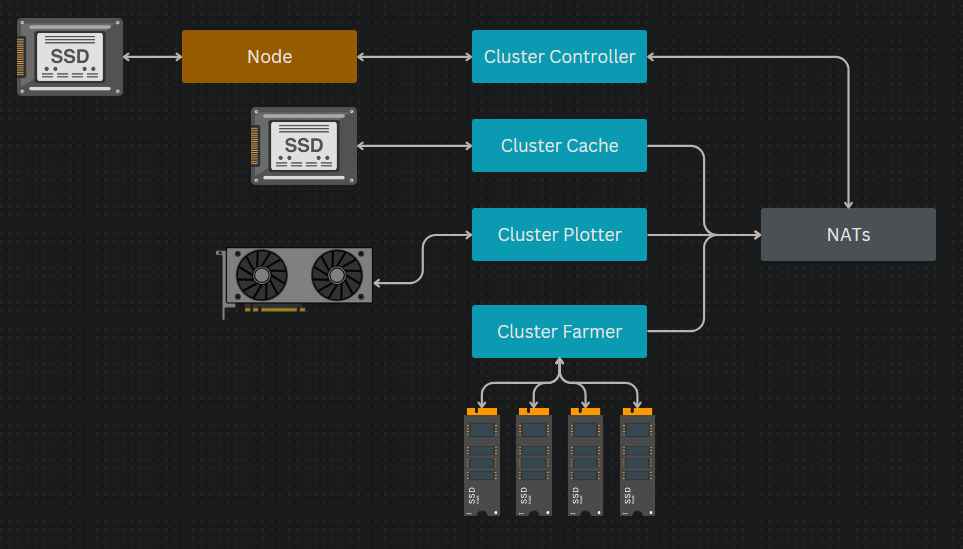
- The Node (which stores blockchain data on an SSD) connects to the Controller. This is NOT part of the cluster, but shown to highlight the relationship
- The Controller is connected to the Node and NATs, this acts as sort of the brains of the Cluster
- The Cache is connected to NATs and stores blockchain data for plotting on an SSD.
- The Plotter is connected to NATs and uses GPU or CPU resources to plot to any Farmers connected to the network.
- The Farmer is connected to NATs and SSDs which will be used to store blockchain data for farming.
Because of how modular a Cluster is, you can add more Plotters if you want to plot faster, more Farmers if you want to farm more space, and more Cache and/or Controllers to increase efficiency. For instance, many users put a Cache on every PC with a Plotter to reduce network traffic.
For redundancy, you can run multiple Controllers and Cache pairs. Additional redundancy can be added for NATs by running a NATs cluster (different than an Autonomys cluster). These more complex topics will be covered in the Advanced Clusters Guide.
Before we continue, let us take a look at a slightly more complex but very common Cluster set up.
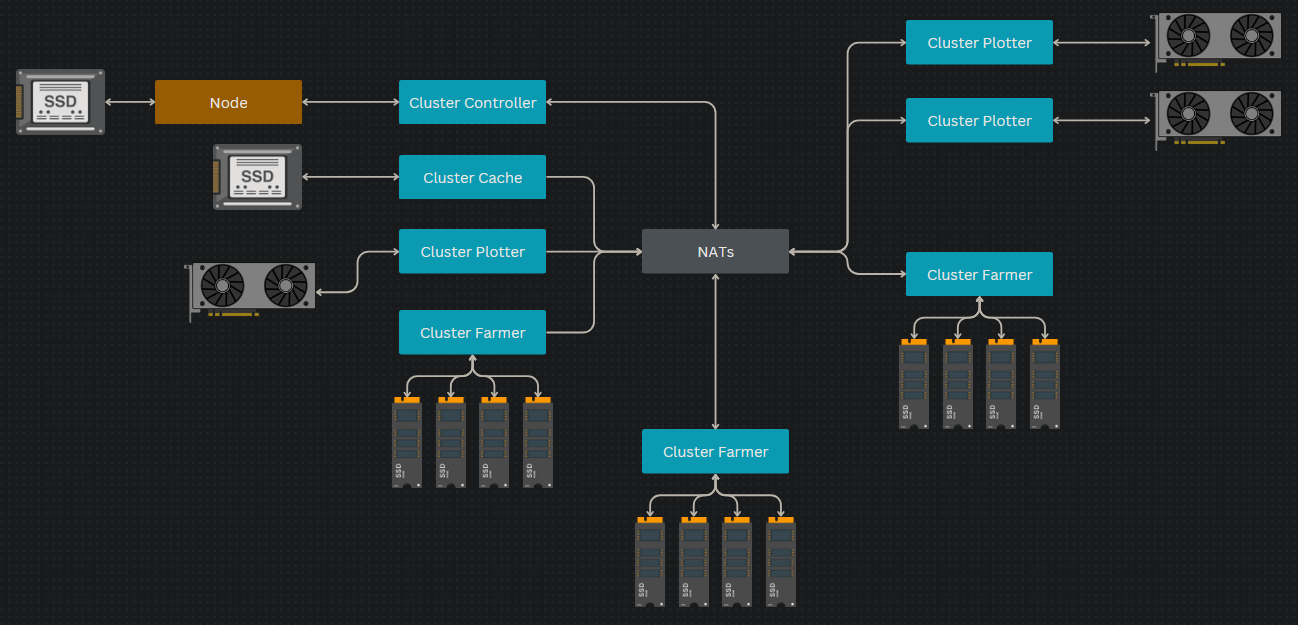
In this setup, we see two addtional Plotters and two additional Farmers. The benefit of Clusters is that you can add many Farmers and Plotters without a lot of additional overhead. Simply connect a new Farmer or Plotter to your Cluster and the Controller with detect it and begin Plotting and Farming.
One thing to make clear is that each PC only needs to run a single instance of a Cluster component. There is no real benefit to running multiple Plotters or Farmers on the same PC. One caveat at the time of writing this guide, is that some people have reported getting more performance out of their GPU plotting by running multiple Plotters. But this will likely not be needed for long and generally should be avoided.
Preparing for a Cluster
Certain components of a Cluster require preperation. We will cover what is necessary for each component below. I prefer to create these directories in my home directory, but you can place them wherever is most convienent. Just make sure your containers reflect the actual path.
NATs
Any PC that will run NATs needs to have a config file specified in the container. I typically put this at the path ~/autonomys/nats. We can do this with a single command which does the following:
- Create a folder in the home directory called "autonomys" and create a sub-directory called "nats" inside it.
- Create a file called "nats.config"
- Add the text
max_payload = 2MBinside the config.
mkdir -p ~/autonomys/nats && echo "max_payload = 2MB" > ~/autonomys/nats/nats.config
Controller
Any PC that will run a Controller needs to have a folder that it can use to store files. I typically put this at the path ~/autonomys/controller and we can create this by running
mkdir -p ~/autonomys/controller
Cache
Any PC that will run a Cache needs to have a folder that it can store the cache files. I typically put this at the path ~/autonomys/cache and we can create this by running
mkdir -p ~/autonomys/cache
Set Appropriate Permissions (required for all components)
For everything to work correctly, we need to set the appropriate permissions. This applies to ALL the folders and files created above. In my examples, everything is inside the ~/autonomys folder, so I can simply run
sudo chown -R nobody:nogroup ~/autonomys/*
If you changed the location of the folders or files, modify the command as needed. To check the permissions are set correctly you can run
ls -l /your/path
Using my example, you should get something like this

Cluster Stack Files
Each component of a Cluster gets deployed as a Docker container. In Portainer, we can add the code for all containers into a single YAML file and deploy everything at once. You will need to use the locations of the folders and files noted above, along with the location of the SSDs your Farmer will plot to in order to successfully deploy the containers.
All-In-One
The first setup we will cover is running a Node + Cluster on one PC. There are multiple benefits to running a Cluster even if you will have everything on one PC. First, you can specify the size of your Cache to be the optimal size for the fastest possible plotting. Second, you will already have a Cluster set up if you ever want to expand. Third, it really is no more difficult than not running a Cluster.
Here is the basic architecture for an all-in-one setup
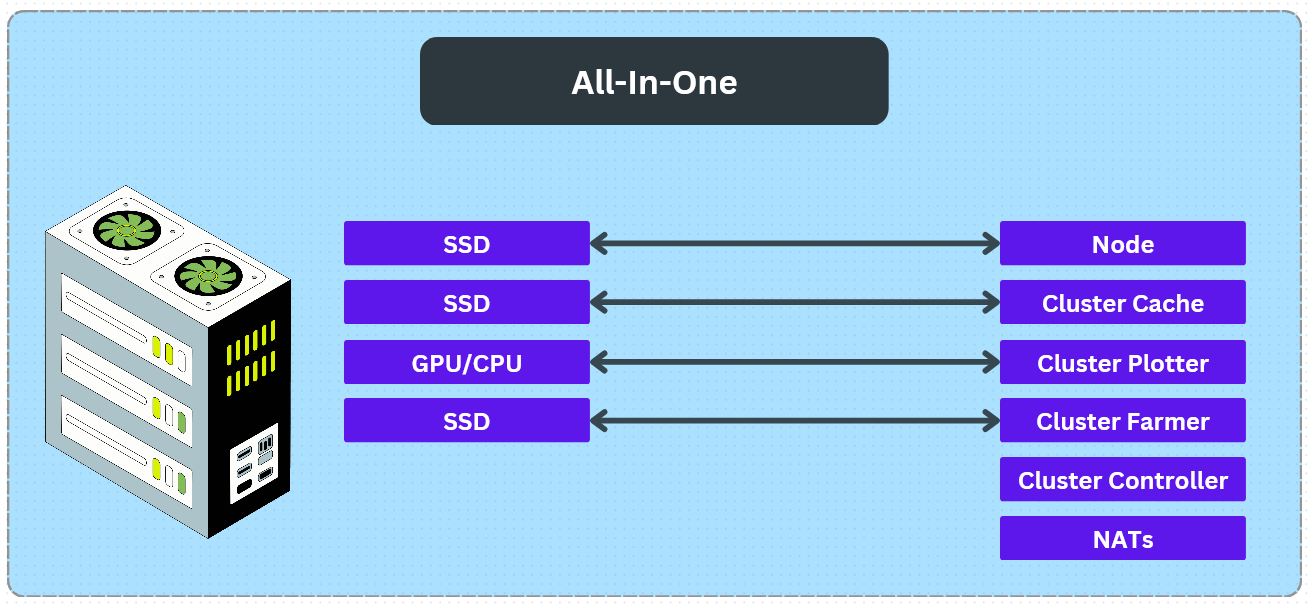
On the left side are the resource we use. You will need an SSD (two shown, but can be 1 SSD with sufficient space) and either a GPU (recommended) or CPU for plotting. The Cluster Farmer can handle lots of SSDs, but requires at least one. On the right side you can see all of the Cluster components needed. In this scenario, the Node has its own stack file, NATs has its own stack file, and the Cluster has its own stack file. This separation is not necessarily required, but I prefer to compartmentalize these operations. On the autonomys_files repo, there is an example YAML for each. Note that you should run the cluster-cpu.yaml if you do not have a supported GPU and the cluster-gpu.yaml if you have a supported GPU.
If you are using an ARM platform like the COMET, you must uncomment the platform: linux/amd64 in the yaml files
Split-Setup
The main benefit of a Cluster is that you can split it up and duplicate it. This is a more complex setup where you have multiple cluster components.
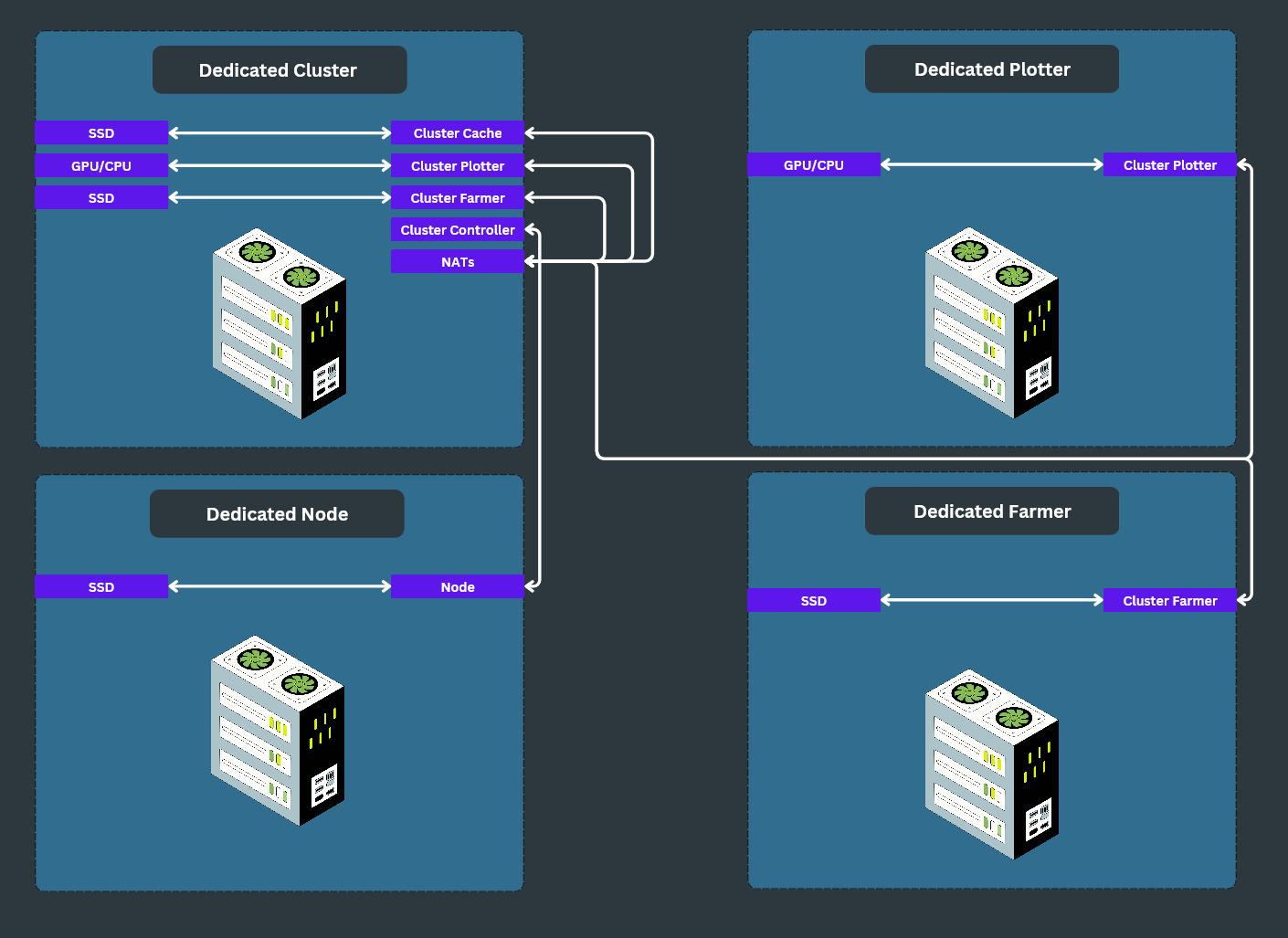
In this example, we see that there is a dedicated Node which handles only Node related things. The Node is connected to the Cluster Controller which is running on a dedicated Cluster. On the dedicated Cluster, the Controller is connected to the Node and NATs. Each of the other Cluster components just attach to NATs. Then there is a dedicated Plotter which is connected to the NATs container on the dedicated Cluster. Last, there is a dedicated Farmer which connects to the NATs container on the dedicated Cluster.
In this example, all Cluster components are being managed by the dedicated Cluster. If that PC goes down, the whole cluster breaks. You could add redundancy here by having the dedicated Plotter and Farmer run NATs and a Controller as well. This topic is covered in Advanced Clusters Guide.
As with the last set up, the files to create this type of setup are found in the autonomys_files repo.
- Dedicated Node would use node.yaml
- Dedicated Cluster would use the nats.yaml and the cluster-gpu.yaml (For GPU Plotting) or cluster-cpu.yaml (For CPU Plotting)
- Dedicated Plotter would use cluster-gpu.yaml (For GPU Plotting) or cluster-cpu.yaml (For CPU Plotting)
- Dedicated Farmer would use farmer.yaml
IP Addresses and Docker
One thing to keep in mind is that the Dedicated Plotter and Dedicated Farmer will need to use the IP address of the Dedicated Cluster to connect to NATs. And the Dedicated Cluster will need to use the IP address of the Dedicated Node to connect the Controller to the Node. The rule of thumb is if the containers are on the same PC they can use the Docker IP or container name. But if they are on another PC you must use their internal IP address.
Here is a demonstrated example
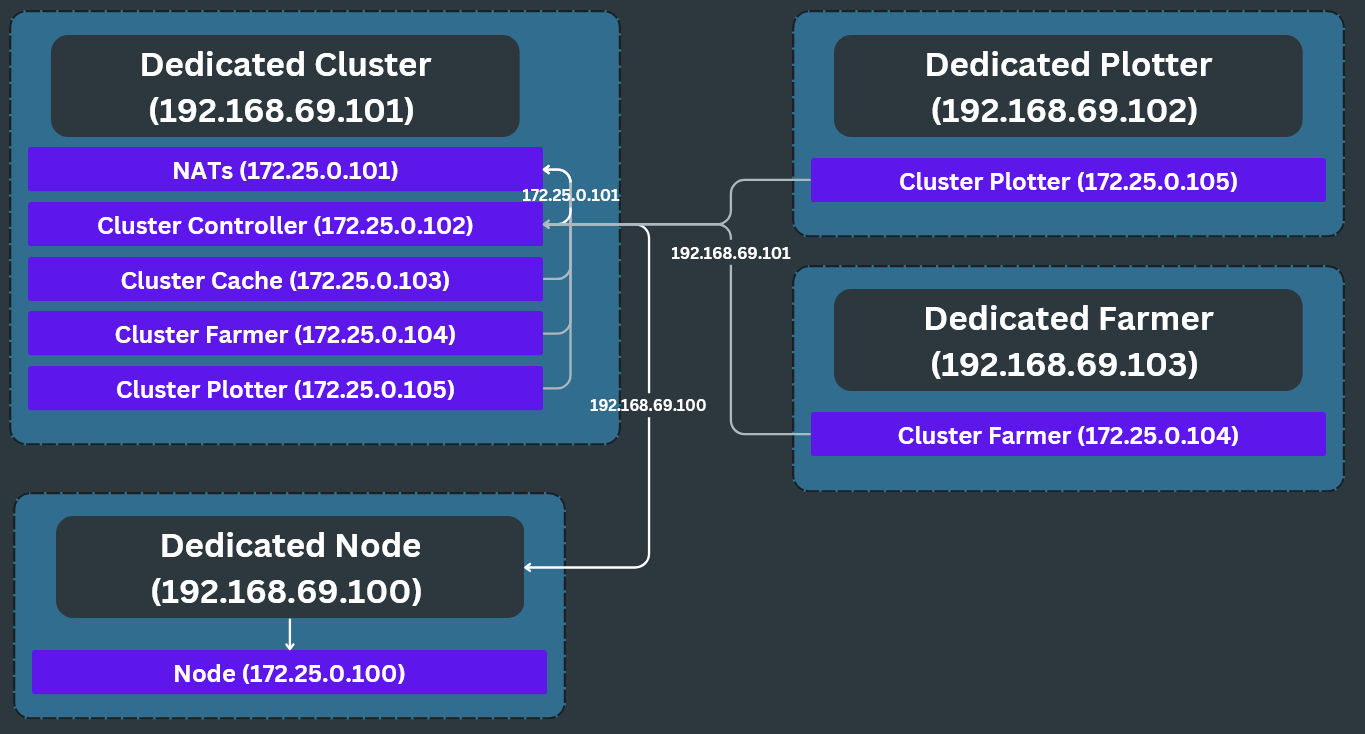
As you can see, the dedicated Cluster uses the Docker IP to make the internal NATs connections. But since the Controller has to reach outside the Docker network to connect to the Node, we need to specify the IP address of the PC hosting the Node, and not the Docker IP. Same with the Plotter and Farmer.
Optimizations
Farmer
Everytime you start your Farmer it will do a benchmark to determine the most efficient proving method. This only needs to be done once to determine if its ConcurrentChunks or WholeSector. Once you know, you can hard code the results into the stack file by modifying the path to something like
path=/farm-1,size=100G,record-chunks-mode=<ConcurrentChunks or WholeSector>